

准确地说,是在container里使用
在Docker中使用GPU
此项目GPU加速基于Nvidia显卡,其他品牌显卡请自行搜索配置TensorRT教程,不能保证运行不出错
Nvidia显卡驱动安装
选择软件和更新 
在附加驱动中安装显卡驱动 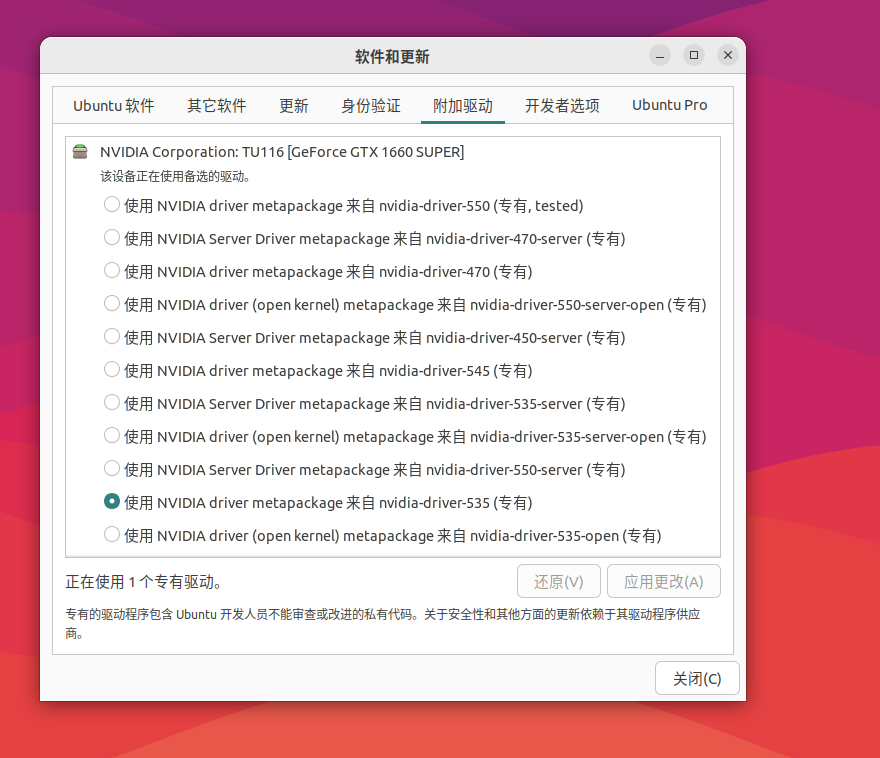
测试是否安装成功:
输入
nvidia-smi
如果出现类似以下输出说明安装成功:
Fri Apr 12 20:55:28 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.161.07 Driver Version: 535.161.07 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce GTX 1660 ... Off | 00000000:01:00.0 On | N/A |
| 40% 35C P8 10W / 125W | 263MiB / 6144MiB | 2% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1044 G /usr/lib/xorg/Xorg 131MiB |
| 0 N/A N/A 1274 G /usr/bin/gnome-shell 58MiB |
| 0 N/A N/A 7083 G ...96,262144 --variations-seed-version 34MiB |
| 0 N/A N/A 103872 G ...erProcess --variations-seed-version 35MiB |
+---------------------------------------------------------------------------------------+
Docker中使用GPU的配置
安装NVIDIA Container Toolkit
进入官网按步骤安装即可: NVIDIA Container Toolkit官网
配置Dockerfile和devcontainer.json
在dockerfile最后加入
ENV NVIDIA_VISIBLE_DEVICES all
ENV NVIDIA_DRIVER_CAPABILITIES compute,utility
Devcontainer.json中加入"--gpus=all"
注意:这是vscode的devcontainer,若在命令行中运行container,在命令后加上
--gpus=all参数即可
GPU加速环境配置(只想使用GPU而不需要CUDA加速可不看此部分)
CUDA 安装
进入docker内,输入nvidia-smi验证驱动是否安装成功
注意:不同电脑GPU型号不同,请在nvidia-smi处查看你最高支持的cuda版本,自行选择合适版本安装,本文仅作为示例
以cuda11.7 + cudnn8.5为例
按下图选择runfile,复制下面两行指令 
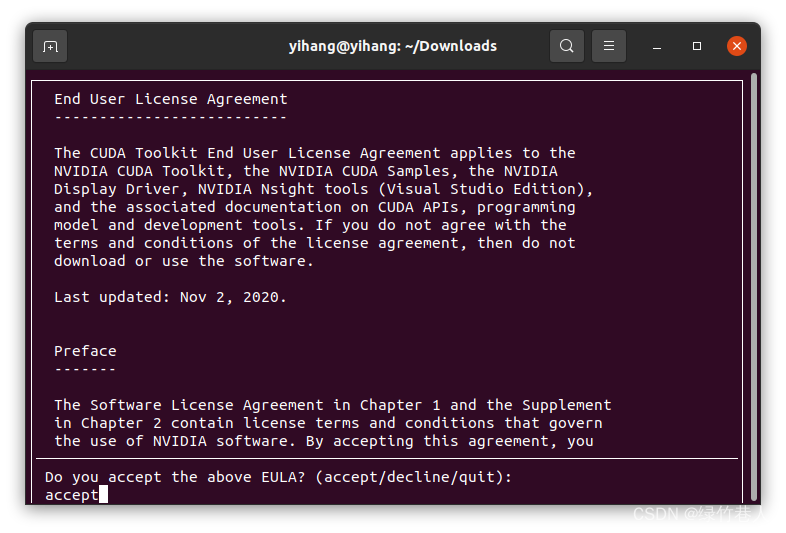
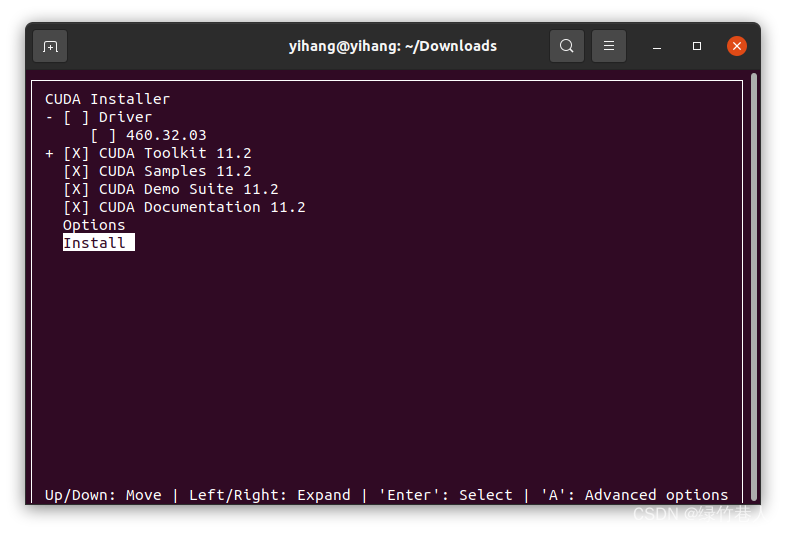
记得取消勾选安装驱动,然后选择install,回车, 接下来就会自动安装了
安装完成后,添加路径:
vim ~/.bashrc
如果你用zsh,改成 vim ~/.zshrc
文件最后增加路径(记得改成你的版本)
export PATH=/usr/local/cuda-11.7/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-11.7/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
让路径生效
source ~/.bashrc
zsh用 source ~/.zshrc
测试安装是否成功
nvcc -V
输出应该类似于
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Sun_Feb_14_21:12:58_PST_2021
Cuda compilation tools, release 11.7, V11.7.152
Build cuda_11.7.r11.7/compiler.29618528_0
Cudnn安装
选择和你的cuda版本匹配的cudnn版本(不推荐9.0.0版本!会导致TensorRT版本过高不支持Tensorrtx, 这里我选择8.6.0)
记得选择
Local Install for Linux x86_64(Tar) 等待下载完成后原地解压
tar -xvf cudnn-linux-x86_64-8.6.0.163_cuda11-archive.tar.gz
更改usr/local/cuda/文件夹下面的include和lib64文件夹的权限:
cd /usr/local/cuda
sudo chmod 777 include
sudo chmod 777 lib64
执行命令复制cudnn的文件进入cuda文件夹(在解压文件夹所在目录执行)
sudo cp cudnn-*-archive/include/cudnn*.h /usr/local/cuda/include
sudo cp cudnn-*-archive/lib/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
验证是否安装成功,执行命令:
sudo cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
输出应该类似于
#define CUDNN_MAJOR 8
#define CUDNN_MINOR 6
#define CUDNN_PATCHLEVEL 0
--
#define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)
/* cannot use constexpr here since this is a C-only file */
安装成功
TensorRT安装
我的CUDA版本是11.7,因此我要选择TensorRT8.4版本(不推荐10.0版本!会导致TensorRT版本过高不支持Tensorrtx)。在网页中找到对应版本,类似于:
TensorRT 8.4 GA Update 2 for Linux x86_64 and CUDA 11.0, 11.1, 11.2, 11.3, 11.4, 11.5, 11.6 and 11.7 TAR Package 这样会下载tar压缩包格式的安装包
解压到你想要的文件夹(你自己记得住就行)
我把TensorRT安装在了/usr/local下
tar -xzvf TensorRT-8.4.3.1.Linux.x86_64-gnu.cuda-11.6.cudnn8.4.tar.gz -C /usr/local/
若解压出错尝试
tar -xvf
解压完成后,添加路径:
vim ~/.bashrc
文件最后增加路径(记得改成你的版本)
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/TensorRT-8.4.3.1/lib
让路径生效
source ~/.bashrc
zsh用 source ~/.zshrc
测试安装是否成功,编译TensorRT的示例,会在bin路径下生成一个针对MINIST数据集的sample_mnist可执行文件
cd /usr/local/TensorRT-8.4.3.1/samples/sampleMNIST
sudo make
cd ../../bin/
./sample_mnist
输出应该类似于
&&&& RUNNING TensorRT.sample_mnist [TensorRT v8000] # ./sample_mnist
[10/14/2022-17:01:44] [I] Building and running a GPU inference engine for MNIST
[10/14/2022-17:01:44] [I] [TRT] [MemUsageChange] Init CUDA: CPU +146, GPU +0, now: CPU 151, GPU 407 (MiB)
[10/14/2022-17:01:44] [I] [TRT] [MemUsageSnapshot] Builder begin: CPU 153 MiB, GPU 407 MiB
[10/14/2022-17:01:45] [W] [TRT] TensorRT was linked against cuBLAS/cuBLAS LT 11.4.2 but loaded cuBLAS/cuBLAS LT 11.4.1
......
为了防止找不到 TensorRT 的库,建议把 TensorRT 的库和头文件链接一下
sudo ln -s /usr/local/TensorRT-8.4.3.1/lib/* /usr/lib/
sudo ln -s /usr/local/TensorRT-8.4.3.1/include/* /usr/include/
如果要使用 python 版本,则使用 pip 安装,执行下边的指令
#TensorRT文件夹下
cd python/
#这里的p37是指python版本为3.7
pip install tensorrt-8.4.3.1-cp37-none-linux_x86_64.whl
Yolov5模型转换
根据你训练模型所用的yolov5版本,git clone yolov5和tensorrtxx
(这里我是yolov5-v7.0和tensorrtx-yolov5-v7.0)
将/tensorrtx-yolov5-v7.0/yolov5中的gen_wts.py文件拷贝到yolov5-7.0目录中,并将模型文件也拷贝到此目录
运行
python gen_wts.py -w your_model_name.pt
生成.wts文件(模型转换的中间文件)
然后进入/tensorrtx-yolov5-v7.0/yolov5
修改src/config.h文件中的CLASS_NUM为你训练的模型的标签类别数
其他较旧版本: 修改
yololayer.h文件中的CLASS_NUM为你训练的模型的标签类别数

修改CMakeLists.txt中的这一段:
...
# include and link dirs of cuda and tensorrt, you need adapt them if yours are different
# cuda
include_directories(/usr/local/cuda/include)
link_directories(/usr/local/cuda/lib64)
# tensorrt
# TODO(Call for PR): make TRT path configurable from command line
include_directories(/usr/local/TensorRT-8.4.3.1/include/) #这两行修改为你的路径
link_directories(/usr/local/TensorRT-8.4.3.1/lib/) #这两行修改为你的路径
...
然后编译
mkdir build
cd build
cmake ..
make
生成可执行文件
然后将.wts文件拷贝到build文件夹中,并执行
./yolov5_det -s your_model_name.wts your_model_name.engine s
其他较旧版本:
./yolov5 -s best.wts best.engine s
生成.engine文件,这便是我们tensorrt部署所需要的模型文件